Вышел KOO Browser 1.0.17
Опубликовано 25 октября, 2020 - 08:39 пользователем Арсен БоровинскийВышел KOO Browser 1.0.17 с обновлением ядра браузера.
Вышел KOO Browser 1.0.17 с обновлением ядра браузера.
15.10.2020 на прошедшем в Томске форуме "Университетская библиотека: #следуйзанами" сделан доклад по применению бесплатной версии ELiS в качестве вузовской ЭБС.
Запись доклада (смотреть с 9:00):
При создании ELiS первым модулем работы с документами был модуль Ebooks. Модуль создает ноды типа ebook и ebookpage для сущности книги и сущностей ее страниц и связывает их.
Т.о. страницы оказывались тоже сущностями связанными с сущностью книги и к страницам можно прикреплять собственные поля.
Но по факту этот функционал никто не использует.
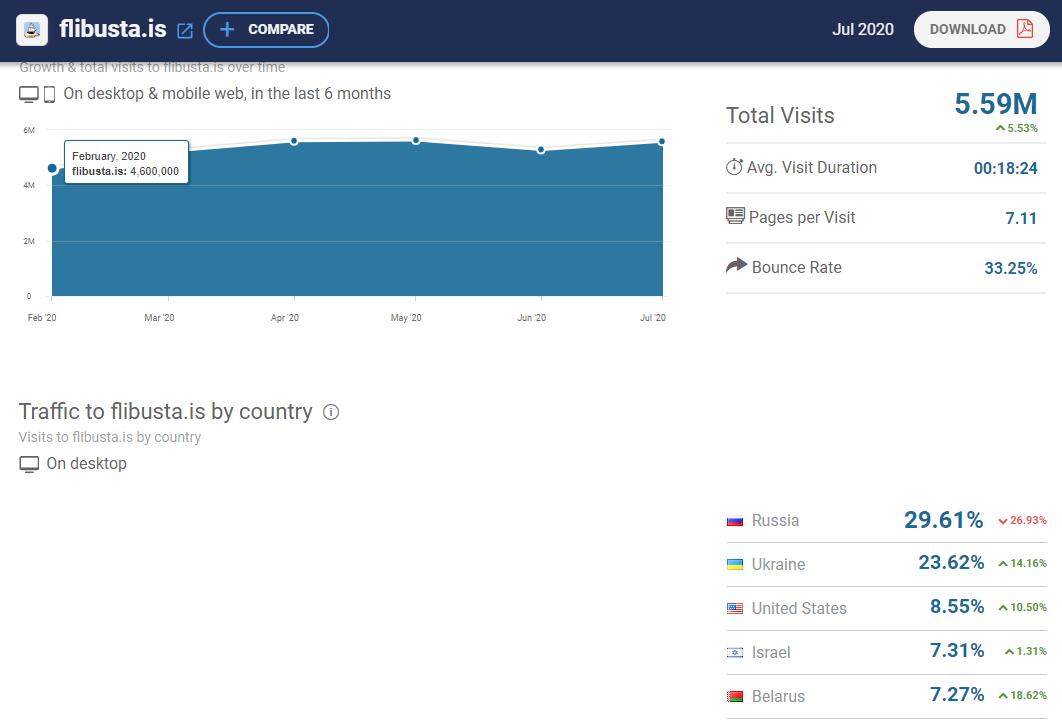
Где региональному образовательному сайту взять художественную литературу для 300 школ региона?
Подобная задача была решена в Пермском крае, где литература размещенная в установке ELiS в краевой библиотеке была встроена с помощью кода вставки в региональную образовательную библиотеку ЭПОС.Библиотека.
Встраивание осуществлено с помощью кода вставки, который есть в ELiS.

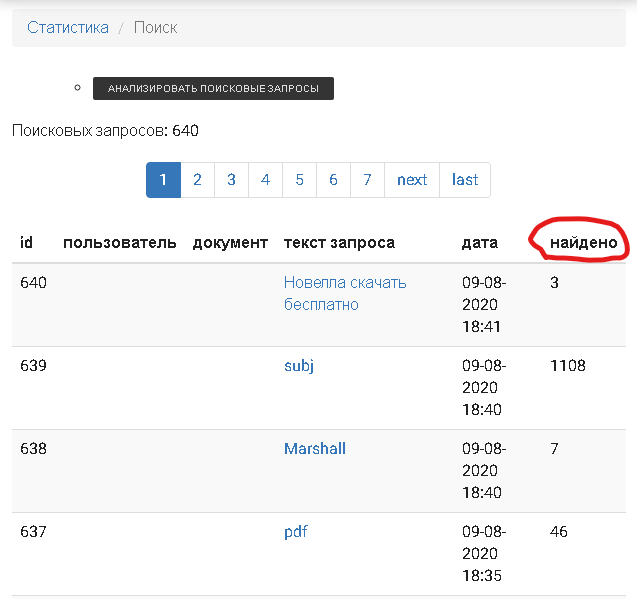
Теперь в отчете по поисковым запросам (на странице reports/elis/search) будет отображаться число найденных документов по данному запросу.
Это позволит оценить корректность сформированных запросов (нашел ли пользователь хоть что-то).
Т.к. раньше эта статистика не велась, по старым запросам будет показываться 0 результатов.

Изначально в ELiS для полнотекстового поиска был использован отечественный поисковый движок Sphinx второй версии. Я собрал для него RPM-пакеты для CentOS7 и CentOS8 (пакеты доступны в открытом репозитории), но только для второй версии (актуальная - третья версия).
Уже достаточно давно существует открытое бесплатное ПО Omeka (теперь эта версия называется Classic).
Относительно недавно было создано следующее поколение Omeka S. Его и рассмотрим в обзоре.