Издатель готовит PDF изначально для печатного издания. Но при размещении в интернете PDF надо специально подготовить, чтобы улучшить пользовательский опыт от взаимодействия с файлом и уменьшить вероятность возникновения проблем с отображением в программах чтения PDF.
В статье рассмотрим случай, когда есть мастер-копия файла PDF и что надо сделать, чтобы подготовить её для продажи или распространение в интернете.
Содержание
- 1 Как PDF отображается
- 2 Типичные ошибки
- 2.1 PDF содержит синтаксические ошибки или несуществующие объекты
- 2.2 PDF не линеаризован
- 2.3 Использование нераспространённых форматов JPEG2000 и JBIG
- 2.4 Отступы
- 2.5 Пустые страницы
- 2.6 Первая страница не является обложкой
- 2.7 Первая страница является разворотом обложки
- 2.8 Нет содержания или в нём мусор
- 2.9 Гиперссылки
- 2.10 Низкий PPI
- 2.11 Двухстраничная вёрстка
- 2.12 Смещение нумерации
- 2.13 Защита от печати
- 2.14 Социальный DRM в виде текста
- 2.15 Неверная кодировка текста
Как PDF отображается[править]
Чтобы отобразить текст и иллюстрации в PDF на экране, требуется специальная программа, аналог Adobe Reader. Почитать можно, например, здесь: https://elibsystem.ru/node/186. Программа разбирает PDF, понимает как его отображать и, в конце концов, рендерит элементы PDF в пиксели на экране устройства пользователя.

Программа может работать как на стороне пользователя (PDF.js), так и на стороне сервера или применять гибридный режим.
Типичные ошибки[править]
PDF содержит синтаксические ошибки или несуществующие объекты[править]
Программы содержат ошибки. Ошибки могут быть не только на этапе чтения PDF и его обработки, но и на этапе записи исходного PDF (т.е. PDF может сам содержать ошибки).
Опасность в том, что распространённые программы чтения обычно стараются не падать при возникновении ошибок и отображать PDF просто игнорируя причины возникновения. В результате в одних программах чтения невалидный PDF читается, а в других нет. Программы чтения никак не подсказывают, что в файле есть ошибка, поэтому можно длительное время не знать, что ваши PDF содержат ошибки.
Обычно проблемы возникают если использовать различные устаревшие программы независимых разработчиков для создания PDF. В распространённом коммерческом ПО создания PDF ошибки встречаются реже.
Если средства валидации показывают ошибку, вам надо понять, откуда она берётся. Возможно вы сможете найти программу вносящую ошибку и замените её чем-то другим или поможет обновление ПО.
PDF не линеаризован[править]
В общем случае чтобы отобразить PDF надо прочитать его целиком. Линеаризация PDF помогает читать только часть PDF для отображения конкретной страницы. За счёт чего программы чтения быстрее проходят по PDF для отображения конкретной страницы в плеере пользователя.
Если вы установите старый Adobe Acrobat Reader (не DC версию), то в нем есть возможность "Cохранить для web", которая и есть линеаризация PDF. См. также fast web view.
Всегда линеаризуйте PDF, это ускоряет и серверный парсинг и парсинг на клиенте.
Использование нераспространённых форматов JPEG2000 и JBIG[править]
PDF может иметь в себе растровые изображения и программы оптимизации PDF могут их сохранять в JPEG2000 из соображений уменьшения объема PDF (JPEG2000 занимает меньше места обычного JPEG). Сам PDF поддерживает JPEG2000, но некоторые программы чтения не умеют работать с этим форматом изображения (например Apache PDFBox) и поэтому лучше от этого формата отказаться в пользу JPEG или PNG.
В издательстве монохромный JBIG применяется реже, но с ним аналогичные доводы, что и с JPEG2000.
Отступы[править]
Желательно убрать все, что связано с обрезкой и чтобы MediaBox, CropBox и TrimBox совпадали.
ПО рендеринга должно само корректно отображать только TrimBox, но по факту может показать на экране пользователя и MediaBox.
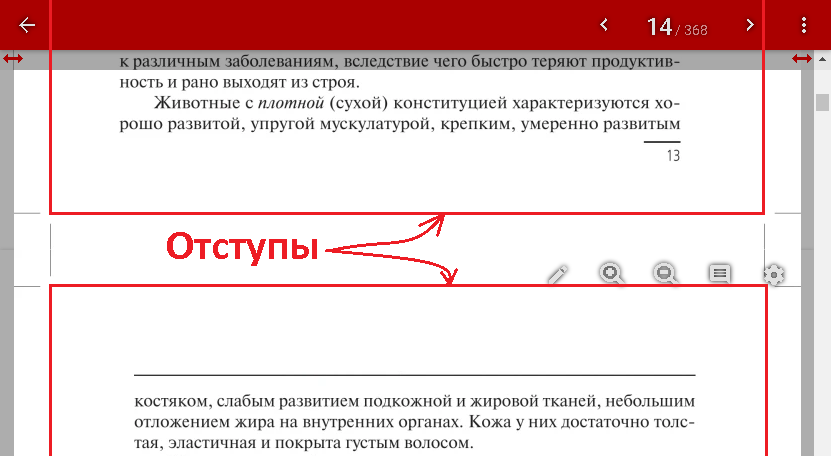
Широкие отступы в PDF для электронного распространения в принципе не особо нужны, зато большие отступы ухудшают читаемость на мобильных устройствах т.к. занимают место на экране, которое могло бы использоваться для увеличения видимого размера букв.
Пустые страницы[править]

Книги могут содержать пустые страницы.
Удалите их из электронной версии PDF т.к. при чтении PDF пользователь может не понимать почему он на странице ничего не видит и думать, что надо подождать, пока страница загрузится. А если он откроет книгу сразу с пустой страницы, может подумать, что программа чтения сломана и сразу уйти.
Первая страница не является обложкой[править]
Первая страница файла PDF должна быть обложкой, если обложка в принципе есть.
Распространение по отдельности обложки и PDF хотя и во многих магазинах возможно, но может быть неудобно на конечных пользовательских устройствах.
Например пользователь видит в магазине файл PDF, покупает его, скачивает, открывает в программе чтения и неожиданно оказывается, что первая страница - это не обложка. А программа чтения не может подтянуть обложку из магазина, поэтому книга так и будет отображаться везде в домашней библиотеке без обложки.
Первая страница является разворотом обложки[править]

В принципе, если бы ПО было поумнее, оно могло бы догадываться, что на первой странице разворот обложки и использовать этот разворот в качестве 3D-обложки, но по факту никто этого не делает.
Нет содержания или в нём мусор[править]

В PDF нет содержания как семантического объекта. Но все используют закладки (bookmarks) для формирования содержания.
Некоторое ПО (Microsoft Word) автоматически формируют закладки из "содержания документа", а содержание формируется когда пользователь выделяет какой-либо текст как "заголовки". Проблема возникает тогда, когда пользователь использует в Microsoft Word семантическую разметку "заголовка" не как семантическую разметку, а как способ увеличить шрифт некоторых слов, в результате в экспортируемом PDF находится в закладках мусор.
Многие электронные библиотеки используют закладки в качестве вывода содержания и поэтому нахождение в закладках мусора сильно бросится в глаза.
По ELiS см: https://elibsystem.ru/docs/book/toc.
Гиперссылки[править]
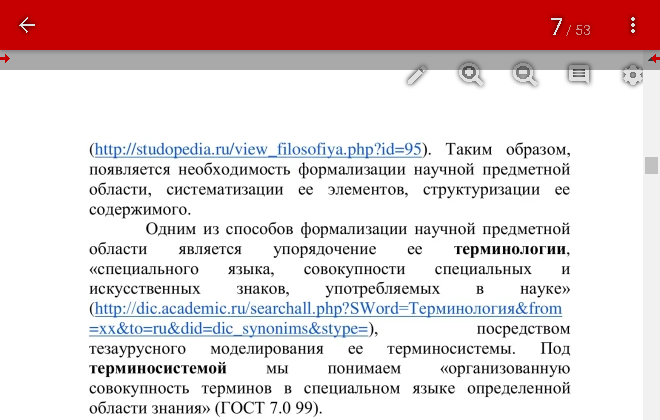
Факт, многие программы отображения PDF в электронных библиотеках не отображают гиперссылки (особенно при серверном рендеринге), поэтому желательно давать такие гиперссылки, которые читаются с экрана и могут быть набраны в браузере в ручном режиме.
Некоторые программы чтения могут также некорректно извлечь гиперссылку, если гиперссылка не влазит в одну строку и переносится на строку следующую.
Пользуйтесь сокращателями ссылок, чтобы ссылки не были слишком длинными. Не используйте перенос гиперссылки.
В ELiS гиперссылки доступны из режима копирования текста.
Низкий PPI[править]
Раньше экраны имели DPI порядка 76-100 точек на дюйм, поэтому были рекомендации существенно уменьшать PPI для размещения документов в интернете.
Теперь большинство покупаемых смартфонов имеют DPI более 320 точек на дюйм (Retina) и разрешение экранов продолжает расти. Поэтому не следует пользоваться старыми инструкциями и устанавливать PPI в слишком низкие значения.
ELiS использует адаптивный рендеринг и оптимизирует изображение под экран пользователя https://elibsystem.ru/node/94, что позволяет оптимизировать размер передаваемого трафика в зависимости от размера экрана пользователя без компромиссов по качеству изображения.
Двухстраничная вёрстка[править]
Не создавайте PDF в виде разворота. Такой PDF можно читать только на больших экранах и сбивается система нумерации страниц.

Смещение нумерации[править]
Бывает, что на первой физической странице файла PDF находится не первая страница с точки зрения логической нумерации книги. Строго говоря, такое смещение в нумерации не является ошибкой, но его лучше не допускать во избежания проблем со ссылками (пользователи начнут путаться, когда программа чтения будет показывать один номер страницы, а на самой странице будет стоять другой номер) и переходами на нужную страницу.
В ELiS есть механизм, позволяющий сдвинуть отображаемую нумерацию, но лучше эту работу произвести ещё на этапе создания PDF.
Защита от печати[править]
Иногда издатель устанавливает в настройках PDF флаг защиты от печати. По сути этот флаг - никакая не защита, а требование к программам чтения не печатать. Проблема в том, что программы серверного рендеринга иногда растеризуют PDF путем печати в рисунок (файл) и если программа-растеризатор выполняет спецификацию PDF, она просто не сможет работать.
Таким образом, этот запрет можно использовать только при прямой продажи файлов, а для распространения в электронных магазинах и электронных библиотеках с собственными PDF-плеерами использовать запрет на печать не следует.
Социальный DRM в виде текста[править]
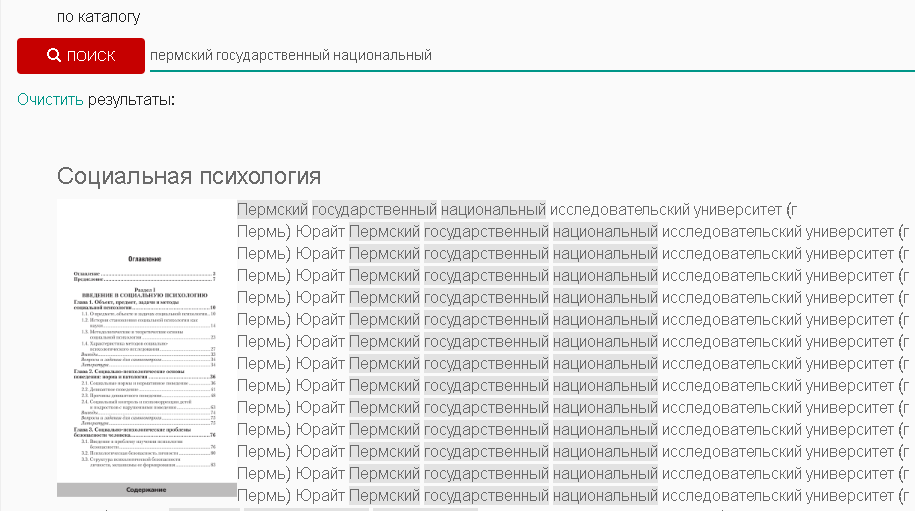
Некоторые издатели, продавая PDF организациям, хотят пометить его, чтобы знать кто допустил утечку, а саму организацию мотивировать условия для утечки незащищённого файла не создавать. Пометки могут быть как текстовыми, так и водяными знаками.
Дак вот: не используйте текстовые пометки с названиями организаций.
Электронные библиотеки организаций извлекают текст из PDF и даже если он будет невидим, он всё равно попадёт в поисковый индекс и будет находиться при поиске. Этот поисковый мусор делает невозможным поиск в электронной библиотеке организации ни по одному из слов, входящих в текст социального DRM.
Неверная кодировка текста[править]
Проблема касается в основном различных экзотических средств генерации PDF, подобных TeX.
Иногда при генерации PDF коды символов выставляются неверно. Т.е. выглядят буквы правильно, но при попытке скопировать их в буфер попадают "кракозябры".
Происходит это от того, что буквы - это на самом деле кривые и целочисленные номера из определенного шрифта. Все системы реально работают не с кривыми, а с целочисленными номерами, но эти номера должны быть привязаны к определенным кодовым таблицами, таким как UTF-8, CP1251 и т.д.
Кракозябры получаются тогда, когда кривые заданы правильно (т.е. выглядят как правильные буквенные символы), а целочисленные номера символов - нет. При копировании, извлечении текста из PDF и т.п. операциях на самом деле копируются и извлекаются целочисленные номера в UTF-8 (потому что в PDF либо ASCII, либо UTF-8) и если номера извлечены неправильные, то за пределами PDF им будут сопоставлены неправильные кривые (т.е. "кракозябры").
Проверить, не кракозябры ли у вас в PDF очень просто, надо открыть его в любой программе (Adobe Reader, Foxit Reader...) и произвести копирование текста и вставку в любой текстовый редактор. Если вставились "кракозябры", значит текст в PDF испорчен и надо разбираться как это поправить.
Вот пример, где сверху то, как текст отображается и то, каким он извлечен из PDF (и попал в поиск) в ELiS:
