Intel продает память Optane с низкими задержками по сравнению с NAND.
Особенности Optane: нет SLC-кеша, DRAM-кеша и все данные сразу пишутся на диск в память 3D XPoint. Интерфейс подключения NVMe.
В NAND-памяти SLC-кеш может быть, может не быть, DRAM-кеш есть в большинстве производительных модулей (только очень бюджетные модели не имеют DRAM-кеша), а серверные модели часто имеют конденсаторы (и работают в режиме writeback всегда, т.е. если в них отправить запись, они сразу отвечают, что ее записали, пока не заполнится кеш так как могут гарантировать запись даже в случае отключения питания за счет встроенных конденсаторов).
Измерять будем на Intel Optane 1600X 120ГБ 3D XPoint NVMe SSD и Intel 660P 2ТБ NAND NVMe SSD. В одном из тестов добавится серверный SATA SSD Kingstone E50 480ГБ.
Содержание
CrystalDiskMark[править]
Методик CrystalDiskMark[править]
Запуск на Ryzen 3600, 32 ГБ ОЗУ DDR4-3200.
Тестовый файл в 1 ГБ не пробивает SLC-кеш Intel 660P.
P.S. в файле ниже есть данные для SSD Samsung 980 Pro 2TB и Crucial P5 Plus CT2000P5PSSD8 2TB, оба nvme, но уже на Ryzen 7950x.
Результаты CrystalDiskMark[править]
У 3D XPoint низкая латентность на чтение и запись блоками по 4K без очереди (15-19 микросекунд), что в 3.4-4 раза меньше NAND.
При случайном чтении с длинной очередью мелким блоком (RND4K) уперлись в процессор, поэтому результаты показывает одинаковые и они не отражают производительность SSD.
При чтении с очередью 8 крупным блоком по 1 МБ NAND SSD опередил Optane. Возможно в виду того, что процессоры NAND заточены на многопоточную работу и более оптимально пишут данные при большой очереди.
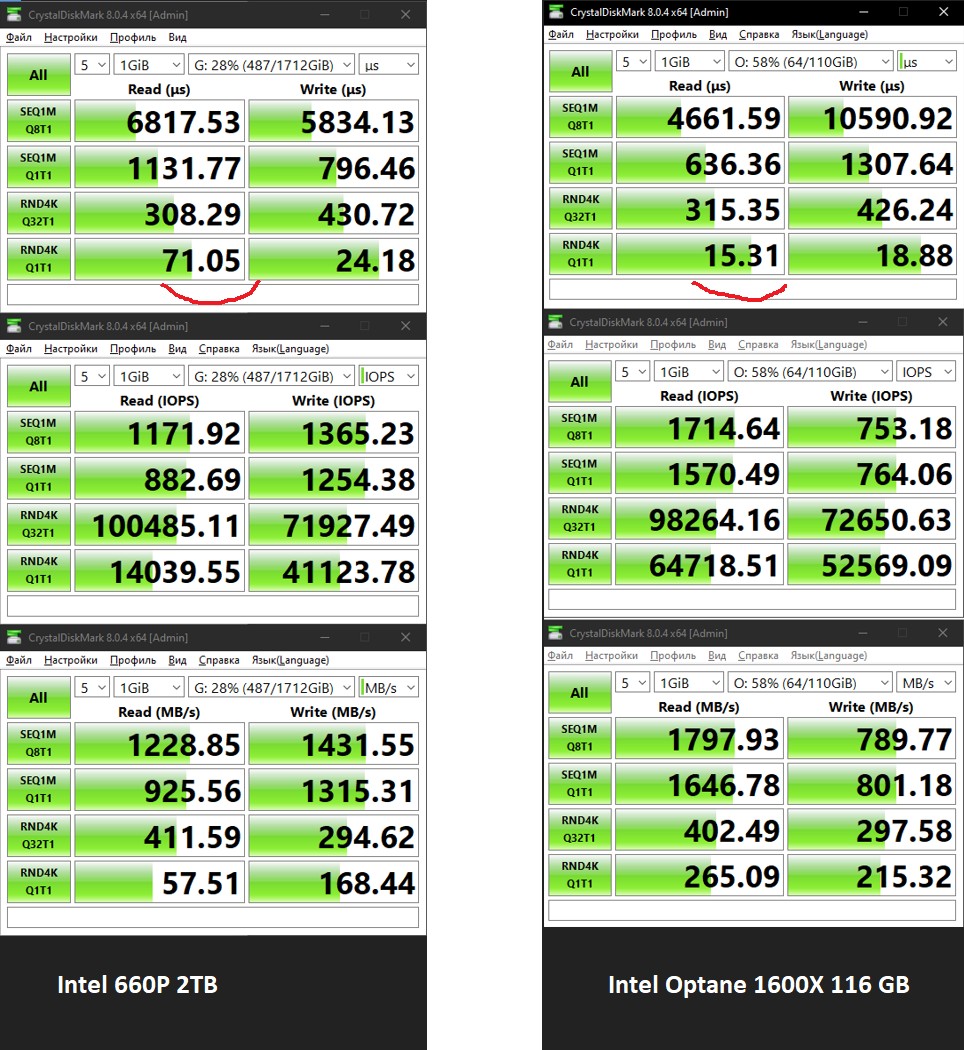
Для SK Hynix PC711:
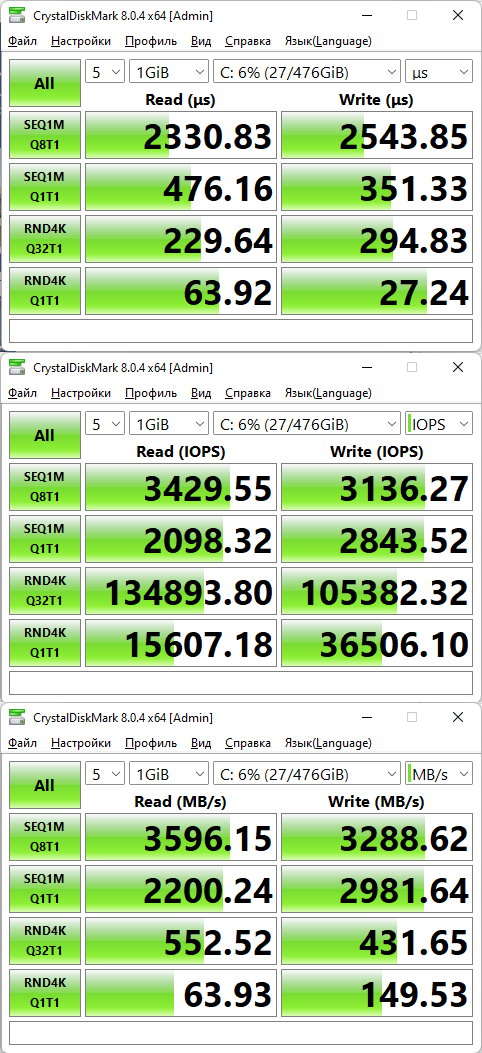
Обсуждение CrystalDiskMark[править]
Optane показывает себя хорошо на мелком блоке с малой очередью. Большой блок и большая очередь позволяют NAND SSD проявить свои оптимизации в управлении записью пусть даже не на такую быструю память.
fio[править]
Тестируем fio прямо на ПК c Windows 10.
Тестовый стенд fio[править]
Два ПК: к Ryzen 3600 добавлен Intel i3-4130 с SSD Kingstone.
Intel Optane 1600X на 120ГБ с интерфейсом NVMe. Ryzen 3600. 32 ГБ ОЗУ DDR4-3200. Win10.
Intel 660P 2ТБ NVMe (десктопная память без конденсатора). Ryzen 3600. 32 ГБ ОЗУ DDR4-3200. Win10.
SATA SSD Kingstone E50 480ГБ (старая серверная SSD с конденсатором) Intel i3-4130 16 ГБ ОЗУ DDR4-2100. Win10. (здесь другой ПК, но в процессор как станет видно ниже не уперлись).
Методика fio[править]
Синтетическим тестом проверяем производительность в fio на блоках 4k и 4M в один поток, но с разной глубиной очереди прямо из под Windows 10.
Предварительно убедились, что от размера используемых файлов в 10ГБ или 30ГБ ничего не зависит.
Размер файлов при этом не пробивает паспортный SLC-кеш Intel 660P и это специально так как в моих кейсах обычно запись случается порциями, которые должны умещаться в SLC-кеш.
Запускаем командами:
Случайная запись мелким блоком по 4k с единичной глубиной очереди и с принудительным fsync после каждого блока:
fio -name=test -direct=1 -runtime=30s -bs=4k -rw=randwrite -iodepth=1 -fsync=1 -size=10G
Случайная запись мелким блоком по 4k с большой глубиной очереди (128):
fio -name=test -direct=1 -runtime=30s -bs=4k -rw=randwrite -iodepth=128 -size=30G
Последовательная запись большим блоком по 4МБ с большой глубиной очереди (16):
fio -name=test -direct=1 -runtime=30s -bs=4M -rw=write -iodepth=16 -size=30G
Случайное чтение мелким блоком по 4k с единичной глубиной очереди:
fio -name=test -direct=1 -runtime=30s -bs=4k -rw=randread -iodepth=1 -size=10G
Случайное чтение мелким блоком по 4k с большой глубиной очереди (128):
fio -name=test -direct=1 -runtime=30s -bs=4k -rw=randread -iodepth=128 -size=10G
Последовательное чтение большим блоком 4МБ и большой глубиной очереди (16):
fio -name=test -direct=1 -runtime=30s -bs=4M -rw=read -iodepth=16 -size=30G
Результаты fio[править]
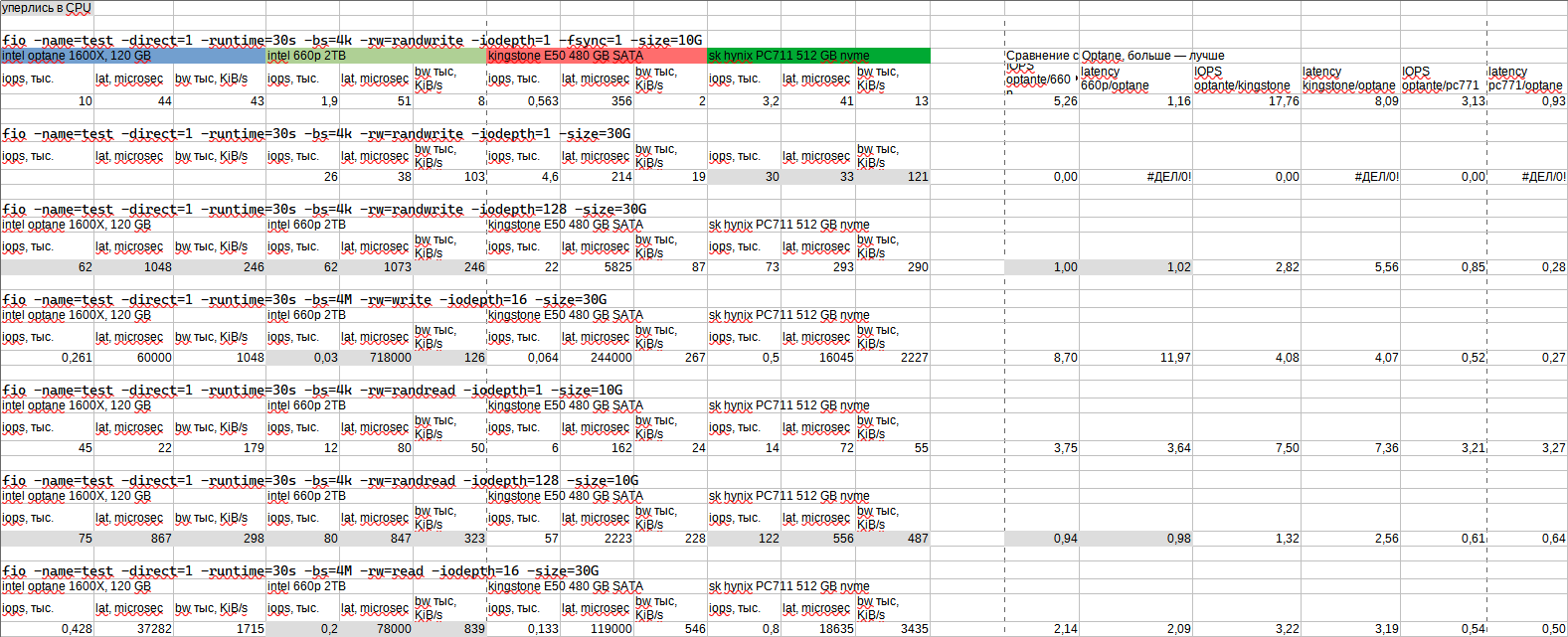
Серым отмечены задания в которых произошло упирание в процессор (т.к. задание однопоточное, оно загружало один поток CPU в 100%) и поэтому серые результаты не отражают разницу между SSD.
Обсуждение[править]
На глубине 128 сравнивать NAND и 3D XPoint не получается так как задача упирается в процессор.
В остальном Optane быстрее NAND в 2-9 раз в зависимости от нагрузки. При этом латентность у Optane лучше от 1 раза (там где fsync) до 12 раз.
Если сравнивать Optane со старым SATA NAND SSD, то разница в IOPS в тестах где не уперлись в процессор в 3-17 раз, а по латентности в 3-8 раз.
Т.о. на синтетике Optane показал себя неплохо и разница может быть в разы, но это зависит от профиля нагрузки.
Также надо учитывать, что Intel 660P - десктопный SSD и при использовании NAND SSD в составе контроллеров с собственным кешем, результаты NAND могут вырасти и разница с дорогим Optane уменьшится.
Касательно IOPS: там где частые fsync (1 тест) Optane выдает всего 10 тыс. IOPS, NVMe NAND 2 тыс. IOPS, а SATA всего 560 IOPS. Т.е. в тяжелой нагрузке никаких паспортных 220 тыс. IOPS вы не увидите.
Если же говорить про запись крупным блоком (4МБ), то Optane выдает паспортные 1 ГБ/c, десктопный 660P всего 126 МБ/c, а старый SATA SSD 267 МБ/c. Но если взять более современные серверные SSD, видимо они тоже будут не сильно проигрывать Optane.
При чтении мелким блоком за счет низкой латентности Optane быстрее в 3.5-4 раза NVMe NAND и в 7 раз SATA NAND.
pgbench[править]
Меня интересует Optane с точки зрения ускорения базы данных.
В синтетике с fio мы видим преимущество Optane, но какой профиль нагрузки будет у PostgreSQL? Ведь PostgreSQL пишет в журнал мелким блоком в один поток, т.е. многопоточной нагрузки не будет.
С другой стороны у Optane низкая латентность чтения (в 3-4 раза ниже NAND), это должно помочь случайному чтению, которое в базах данных случается.
Тестируем с помощью pgbench, которые производит чтения и вставки в три таблицы с разным числом одновременных клиентов, которые создают конкурентность подобную использованию веб-сервисов одновременно несколькими пользователями.
Но в этот раз используем PostgreSQL внутри виртуальных машин под управлением Hyper-V.
Тестовый стенд pgbench[править]
CPU Ryzen 3600, Windows 10, 32 ГБ ОЗУ 3200.
Intel Optane 1600X 120ГБ NVMe.
Intel 660P 2ТБ NVMe (десктопная память без конденсатора).
На компьютере под Hyper-V разворачивался Oracle Linux 8.5 и производилась установка fio и pgbench c PostgreSQL. Дальше виртуальная машина клонировалась и переносилась с Optane на NAND SSD.
Результаты pgbench[править]
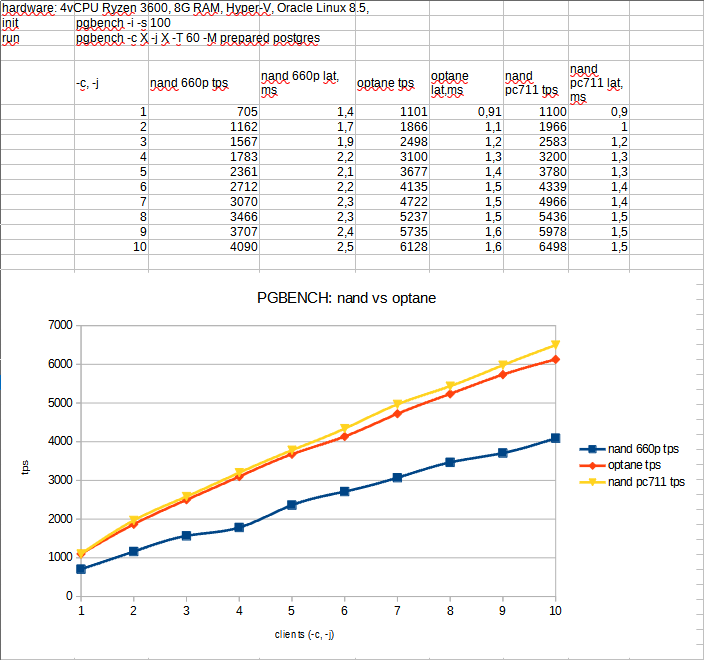
Результат достаточно линеен и Optane быстрее всего на 40-50%:
Скорость записи при выполнении теста в пределах 20-100 МБ/c запись, чтение примерно в два раза меньше записи по показаниям ОС (там сам тест такой, что записи больше).
По показаниям ОС Optane при этом загружен на 10-25%, NVMe NAND на 40-60%.
Обсуждение pgbench[править]
Так есть ли смысл использовать Optane для баз данных?
Общее время выполнения запроса (которое для пользователя критично) = время работы БД + время работы кода сервера приложений. Разделение по времени здесь разное, в зависимости от числа запросов в базу (и их сложности) и от сложности логики в сервере приложений.
В моем случае часто это 50%/50%. Optane не ускорит код сервера приложений так как в веб-сервисе все уже в файловом кеше и чтение с файловой системы происходит редко. Поэтому Optane ускорит прежде всего базу данных.
Здесь тоже горячие данные уже в кеше базы данных, поэтому Optane будет полезен или в больших базах, у которых база не влазит в кеш ОЗУ или там где много записи (и то смотри выше про кеш контроллера).
Также Optane будет видимо полезен, если у вас нагрузка на базу очень велика и вы ищете способ хотя бы временного вертикального масштабирования.
По pgbench (который пишет примерно в 2 раза больше чем читает по данным ОС) выходит, что Optane не слишком полезен для сценариев использования PostgreSQL в не слишком тяжелых веб-нагрузках.
Это стоит пояснить: представим ситуацию, что страница генерируется за 50 мс, из которых 25 приходится на работу с базой данных, а 25 на работу кода. Тогда ускорение в два раза базы данных уменьшает время генерации страницы на 12 мс и ускорение от Optane с 50 до 38 мс. Да ускорение, но не слишком заметное.
Готовы ли вы переплачивать за Optane в таком случае - решать вам.