Раньше я уже делал доклад по поисковой оптимизации электронных библиотек и звучали слова, что тот факт, что поисковики не будут отправлять пользователей в полугиговые PDF существенно уменьшает число поисковых запросов, на которые электронная библиотека попадёт в выдачу.
Но как оценить, насколько существенно это может повредить?
А можно измерить сколько уникальных слов встречается в заглавии ресурса и сколько в тексте.
Для этого написан небольшой скрипт, который извлекает текст из заглавий и из содержимого и можно сравнить сколько уникальных слов находится в заглавиях и сколько в тексте.
Для очистки от мусора, оставлялись только латинские и русские буквы, a-zA-Zа-яА-Я, а всё остальное вырезалось. Другой обработки слов не осуществлялось, в том числе слова не приводились к нормальной форме.
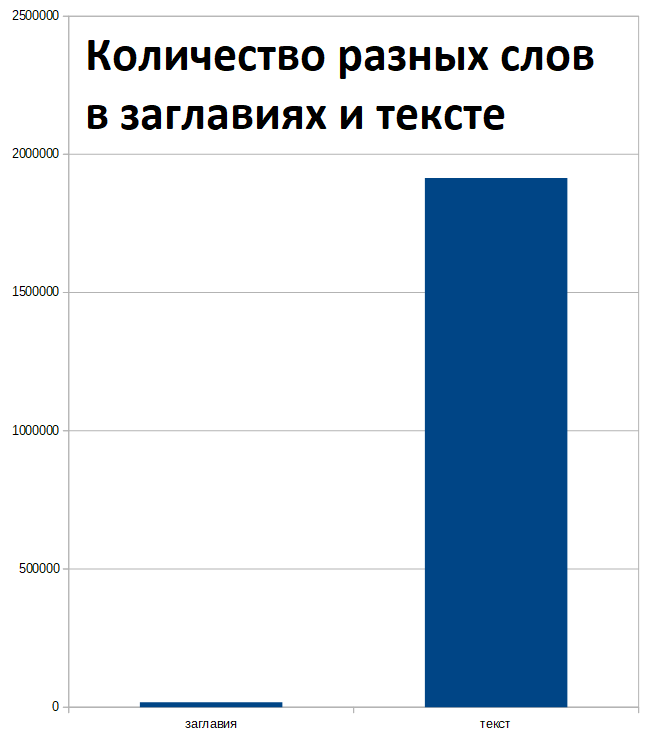
Анализ показал на примере https://elis.psu.ru, что на 9550 проанализированных документов (PDF, EPUB и т.п.) в заглавиях содержится 17292 разных слов, а в тексте 1914810 разных слов.
Т.о. в текстах в библиотеке содержится в 110 раз больше слов, чем в заглавиях.
Код[править]
Пример кода для подсчета слов:
<?php
require_once('drupal.bootstrap.php');
ini_set('memory_limit','10G');
module_load_all();
$words_title = array(); // only title words
$words_text = array(); // all text words
gc_enable();
$nodes = db_select('node','n')->fields('n')->condition('n.status','1')->condition('n.type','ebookpage','<>')->execute();
$i = 0;
foreach ($nodes as $res) {
$node = node_load($res->nid);
if ($node != false) {
addWordsToArray($node->title, $words_title);
$i++;
$elisSearch = new ElisSphinxSearch();
$textFragments = $elisSearch->getTextFragmentsForEntity($node,'node');
if ($textFragments != false) {
foreach ($textFragments as $fragment=>$text) {
if ($text != null && is_string($text)) {
addWordsToArray($text, $words_text);
}
}
}
if ($i % 10 == 0) {
drupal_static_reset();
print "$i titles: " . count($words_title) . ' texts: ' . count($words_text) . "\n";
}
}
}
print "title word count: " . count($words_title) . "\n";
print "text word count: " . count($words_text) . "\n";
function addWordsToArray($str, &$arr) {
$words = preg_split("/\s|\n/", $str);
foreach ($words as $word) {
$word = preg_replace("#[^A-Za-zЁЙЦУКЕНГШЩЗХЪФЫВАПРОЛДЖЭЯЧСМИТЬБЮёйцукенгшщзхъфывапролджэячсмитьбю]#","",$word);
if (is_string($word) && strlen($word)) {
if (!isset($arr[$word])) {
$arr[$word] = 1;
} else {
$arr[$word]++;
}
}
}
}