Часто возникает вопрос сервер какой конфигурации выбрать. Нужно ли больше ядер или нет.
Проведен с помощью pgbench тест TPC-B, эмулирующий покупку товара в магазине.
Содержание
Тестовое окружение[править]
2 процессора Xeon E5-2690v2 (в каждом 10 ядер, 20 потоков). В сумме 20 ядер и 40 HT-потоков частотой 3 ГГц и 3.6 ГГц TurboBust.
Виртуальная машина CentOS 8 x64 под управлением Hyper-V в Windows Server 2012 (первое поколение ВМ).
ОЗУ на сервере 128 ГБ, но ВМ доступно 64 ГБ.
vCPU: 38 шт.
Дисковая система: RAID 10 из 4 SSD Intel SSD DC S3500 по 800ГБ на контроллере Adaptec 6805 (контроллер имеет производительность где-то на уровне 30-40 тыс. IOPS. Но в процессе тестирования в основном бенчмарк генерировал нагрузку в 2000 IOPS, т.е. сильно меньше потолка контроллера.
В ОС запись без подтверждения отключена.
Конфигурация PostgreSQL[править]
max_connections = 100 shared_buffers = 8GB effective_cache_size = 24GB maintenance_work_mem = 2GB checkpoint_completion_target = 0.7 wal_buffers = 16MB default_statistics_target = 100 random_page_cost = 1.1 effective_io_concurrency = 200 work_mem = 20971kB min_wal_size = 1GB max_wal_size = 4GB max_worker_processes = 38 max_parallel_workers_per_gather = 4 max_parallel_workers = 38 max_parallel_maintenance_workers = 4
Методика[править]
Методика pgbench[править]
Запускается с помощью pgbench тест TPC-B (имитирующий транзакции в интернет-магазине), который проводится в течении 100 секунд.
Размер тестовой базы (см. du -hs /var/lib/pgsql/12/data) составляет менее 5 ГБ и целиком помещается в кеш PostgreSQL.
Запускается с разным количеством потоков, причем число потоков равно числу клиентов. Строится график числа транзакций в секунду.
В первый проход считаются операции и чтения и записи, во второй проход только чтения (из ОЗУ т.к. все файлы PostgreSQL целиком помещаются в память и при чтении обращения к SSD не происходит).
Дополнительно запускается тест sysbench --threads=X cpu run также для различного числа потока и строится график числа событий в секунду (events per second)
Запуск теста pgbench[править]
Подготовка таблицы pgbench:
su postgres psql create database pgbench with owner = postgres; \q cd /usr/pgsql-12/bin ./pgbench -s 100 -i pgbench
Запуск производился с вариацией числа X процессов:
./pgbench -c X -j X -t 100 pgbench
Т.е. для 1 процесса запуск был:
./pgbench -c 1 -j 1 -T 100 pgbench
Для 38 процессов запуск был
./pgbench -c 38 -j 38 -T 100 pgbench
Для исследования теста с задачами только чтения необходимо добавить параметр -S
./pgbench -S -c 38 -j 38 -T 100 pgbench
Результаты[править]
Производительность pgbench TPC-B в смешанной нагрузке и только в чтении[править]
Первый график соответствует запуску pgbench как с операциями чтения, так и записи, второй график соответствует тесту только с операциями чтения, при которых дисковая система вообще не задействуется.
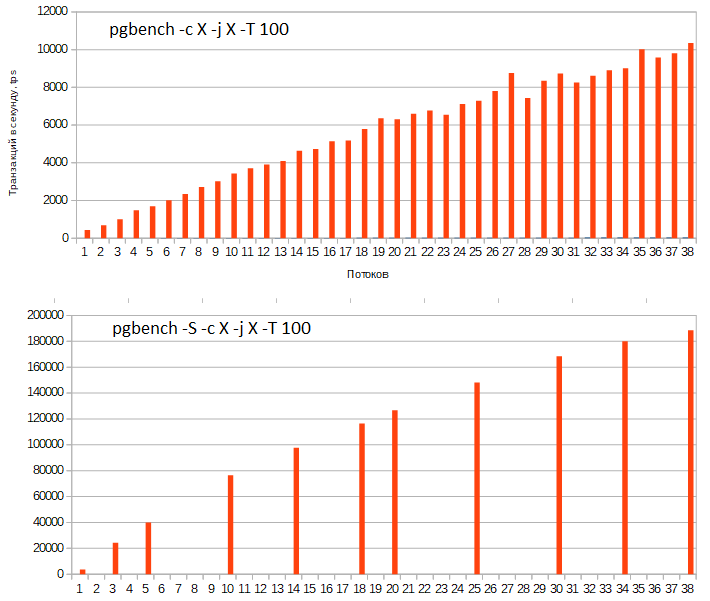
Для всех тестов число IOPS колебалось между 1400 и 2400, а типичное было около 2000 IOPS. Хотя производительность в процессе выполнения теста в IOPS могла колебаться на десятки процентов, колебаний в десятки, что бывает на бытовых SSD при заполнении SLC-кеша, не было.
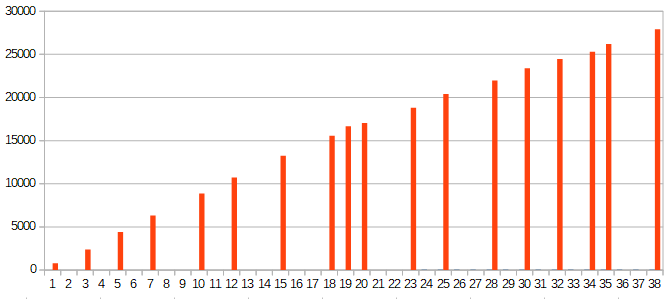
Производительность процессора в sysbench[править]
Аналогично есть излом прямой на числе физических ядер и совершенно одинаковая разница в производительности с включением Hyper-Threading в 63%.
Выводы по pgbench[править]
В целом графики похожи на бенчмарки других компаний, тестировавших PostgreSQL. Но когда смотрите на графики, на которых сотни тысяч tps, обращайте внимание, не идёт ли речь только о чтении (без записи) т.к. при записи в TPC-B число транзакций драматически уменьшается даже на SSD.
- PostgreSQL очень эффективно использует Hyper-Threading: прирост от наличия HT составляет более 60% как в тесте с записью, так и с чтением!
- График можно разделить на две части, в первой половине число потоков не превышает числа физических процессоров, во второй превышает. И там и там от числа потоков линейный рост, но наклон разный. Т.о. у PostgreSQL великолепная вертикальная масштабируемость.
Но не была ли дисковая система узким местом? 2 тыс. IOPS - это для SSD не слишком много, может где-то затык по работе с дисками?
Тестирование дисковой подсистемы[править]
В тестировании уменьшено число ОЗУ ВМ до 2 ГБ для уменьшения влияния кеша дисковой подсистемы. Однако измерения показали, что чтение при этом производится из кеша хоста (Windows Server). В остальном стенд без изменений.
Методика sysbench fileio[править]
В начале в один поток измерялась скорость случайных чтения/записи в течении 100 секунд на файле в 50 ГБ командой:
sysbench --file-total-size=50G --file-num=1 fileio prepare sysbench --file-total-size=50G --file-num=1 --file-test-mode=rndrw --time=100 --file-rw-ratio=X fileio run
Варьировался процент операций чтения к записи от 0.1 до 10.
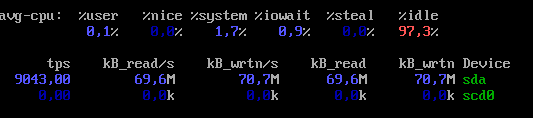
Затем аналогичные измерения повторялись с увеличением числа потоков (--threads 20, 38), но с меньшим шагом по отношению операций чтения к записи, т.к. на предыдущем этапе было видно, что ничего интересного на малом шаге нет.
Дальше делалось измерение последовательной записи и последовательного чтения с вариацией числа потоков командами:
sysbench —num-threads=1 –file-total-size=50G --file-num=1 --file-test-mode=seqwr —time=100 sysbench —num-threads=1 –file-total-size=50G --file-num=1 --file-test-mode=seqrd —time=100
При всех тестах в гостевой ОС ни одно ядро не загружалось на 100%:
Результаты тестирования чтения и записи[править]
Случайные чтение/запись с 1 потоком[править]
Производительность на запись выше, чем производительность на чтение (кеш контроллера - 512 Мб). И это при том, что чтение фактически идет из ОЗУ хоста Windows Server.
С увеличением доли чтения, падает число IOPS с 17 тыс. до 8 тыс., а пропускная способность с 270 до 120 МБ/c.
При этом производительность может испытывать случайные просадки, есть колебания.
Средняя латентность растёт с ростом доли чтения с 0.08 мс до 0.12 мс, 95 перцентиль колеблется от 0.10 до 0.20 мс. Максимальная задержка растет с долей числа чтений до 142 мс.

Случайные чтение/запись с 20 потоками[править]
Увеличение числа потоков до числа физических ядер увеличивает производительность и в IOPS и в пропускной способности.
Но также увеличивается и латентность.
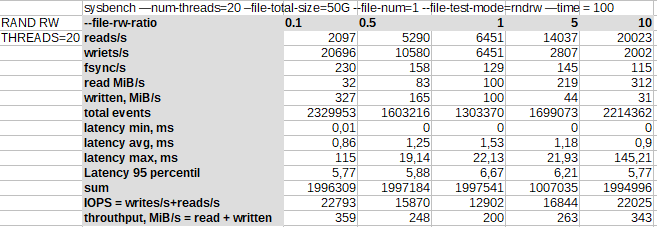
Случайные чтение/запись с 38 потоками[править]
Увеличение числа потоков до доступных в гостевой ОС числе ядер еще немного увеличивает производительность, но с еще худшей латентностью.
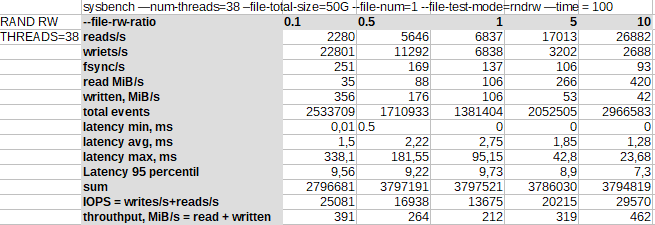
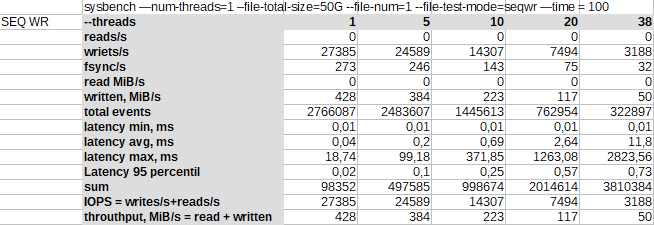
Последовательная запись[править]
В последовательной записи нет влияния кеша хоста на чтение, здесь демонстрируются возможности именно работы с дисками.
В результате максимальный IOPS достигается при одном потоке в 27 тыс. IOPS и с увеличением числа потоков производительность быстро падает до 3 тыс. IOPS.
Обычно SSD любят, когда в них пишут с большой очередью, в чем дело? Возможно в переключении контекста или в том, что одновременный доступ не любит контроллер.
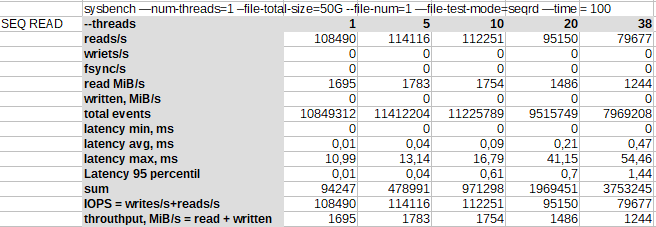
Последовательное чтение[править]
Последовательное чтение фактически ведется не с диска, а с ОЗУ хоста, поэтому достигается пропускная способность в 1.8 ГБ/c. Также наблюдается рост латентности с ростом числа потоков.
Валидация тестирования в других окружениях[править]
Были сделаны замеры на Ryzen 3600/ Win10/ Hyper-V и одиночном NVMe SSD на 2 ТБ десктопного уровня Intel 660p. Настольный NVMe SSD был быстрее и по пропускной способности и по латентности тестового стенда от 1 до 2 раз в зависимости от теста, причем на большом числе потоков результаты приближались к тестовому стенду.
Также произведено тестирование sysbench fileio на bare metal под управлением CentOS8. Определенные отличия были, но если в основном была запись, то несколько быстрее работало под управлением Hyper-V, а когда было больше чтения, быстрее работала bare metal CentOS8.
Дополнительно проведены тесты sysbench под Hyper-V, KVM, baremetal на этом же сервере: https://elibsystem.ru/node/503
Выводы по файловой системе[править]
- ОЗУ хостовой ОС может эффективно использоваться в качестве кеша.
- Слабым звеном является контроллер, который выдавал внешнюю производительность на RAID10 до 27 тыс. IOPS. Тесты похожи по величинам на те, что уже есть на контроллер.
- Увеличение числа потоков чтения и записи может приводить не к увеличению, а к уменьшению производительности.
- Латентность с ростом числа потоков может быстро увеличиваться, также возникает небольшое количество задержек в сотни миллисекунд, и даже больше секунды!
- При однопоточной работе можно рассчитывать на латентность порядка 0.1 мс.