Существует совсем немного подходов подсчета статистики по книгам (или документам) в электронных библиотеках (ЭБ). Можно:
- Анализировать логи веб-сервера.
- Установить внутренние счетчики на скачивание страниц или файлов целиком (по некоторому URL, по которому доступен ресурс).
- Установить асинхронные счетчики в плеерах документов, которые будут отправлять информацию на сервер об чтении того или иного документа.
Рассмотрим достоинства и недостатки каждого из методов.
Содержание
Методы сбора статистики[править]
Логи веб-сервера[править]
Каждое обращение на веб-сервер записывается в текстовый файл, в котором указывается обязательно URL, по которому было обращение и, часто, параметры обращения (ip-адрес пользователя, UserAgent и т.д.). Затем уже самостоятельно парсятся и из них составляется некоторая общая статистика.
Плюсы:
- Легко прикручивается к любой библиотеке, даже если она сама не имеет никакого статистического функционала.
- Все настройки ведутся на веб-сервере, соответственно, не трогается код электронной библиотеки.
- Не создается нагрузка на библиотеку для хранения логов.
Минусы:
- Логи надо уметь правильно фильтровать. Обычно в логи попадают все запросы на все ресурсы и если не отфильтровать результаты обращений, то можно получить 10-40 кратное завышение количества обращений из-за попадания в лог статических файлов.
- В некоторых случаях полностью отфильтровать ненужное и оставить нужное невозможно, т.е. способ может не подходить для конкретных ЭБ.
- Необходимо отфильтровать поисковых роботов, которые могут давать трафик превышаюший органический (запросы от людей).
- Парсинг файлов может быть длительной процедурой, т.к. результаты извлекаются путем парсинга каждой строки.
- Веб-сервера, обычно, проводят ротацию логов и надо позаботиться об их сохранности.
- Такие логи ничего не знают про сессии, хотя могут записывать ip-адрес. Пользователи за NAT будут при таком подходе выглядить как один пользователь.
Я бы советовал использовать такой подход только в крайнем случае. В руках непрофессионалов он будет давать существенное завышение статистических сведений. Также, обычно, логируются только GET-запросы и если у вас, например, поиск осуществляется POST-запросом, то в логи такой запрос по-умолчанию не попадет.
При грамотной настройке веб-сервера, совместимости с электронной библиотекой, корректном парсинге и фильтрации неорганических запросов точность счетчика будет близка к точности внутреннего счетчика и давать завышенную страницевыдачу на несколько десятков процентов.
Внутренние счетчики[править]
Обычно в современных плеерах страницы книги разбиты на отдельные файлы (рисунки) и каждое скачивание страницы для отображения в плеере можно записывать в базу данных.
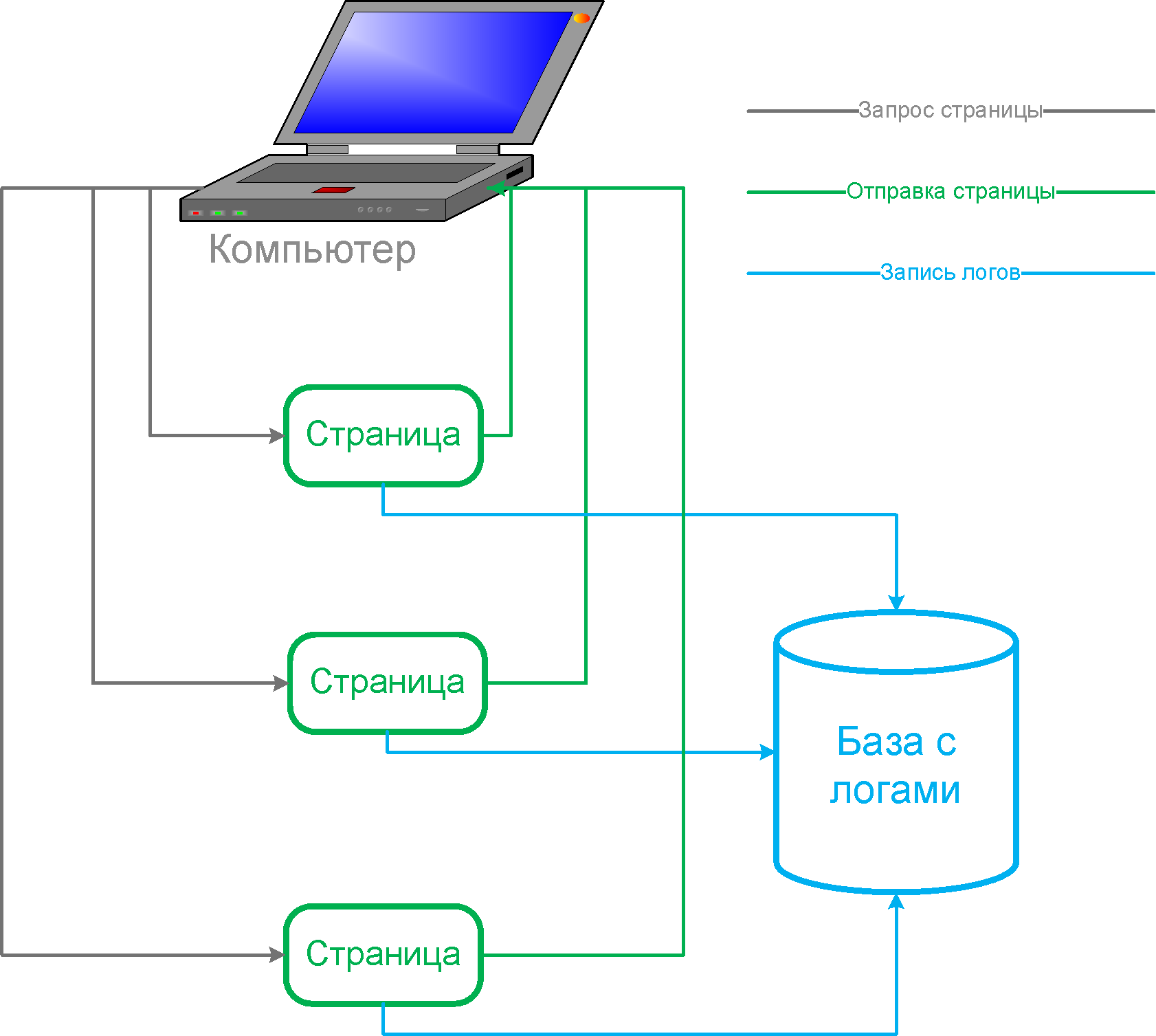
Плюсы:
- Возможен очень подробный трекинг чтения книги конкретным пользователем (знание кто когда и какую страницу читал).
- Не зависит от способа обращения к странице и не требуется интеграция в плееры (работает с любым плеером).
- Позволяет вести надежный учет конкурентных лицензий.
Минусы:
- Быстрое разрастание базы с логами и необходимого для нее места.
- Из-за большого размера базы, построение годовых отчетов требует большого количества времени и рекомендуется предварительная агрегация.
- Завышение статистики из-за предварительного кеширования на клиенте.
- В некоторых реализациях может фиксировать показ обложки книги в каталоге или в результатах поиска как книговыдачу (т.е. завышать книговыдачу и, при этом, уменьшую среднее число просмотренных страниц на книговыдачу).
- В некоторых реализациях возможно существенное завышение страницевыдачи из-за активности поисковых роботов.
Данный подход рекомендуется, если вы хотите вести точный трекинг чтения страниц и предприняты меры, предупреждающие завышение статистики поисковыми системами. Наличие упреждающего кеширования в любом случае будет вносить искажения в записываемые данные.
При грамотной реализации страницевыдача будет завышена на несколько десятков процентов.
Счетчик в книжном плеере[править]
Счетчик интегрируется непосредственно в плеер, по мере просмотра страниц в книжном плеере, на сервер отправляются данные о просмотренных страницах.
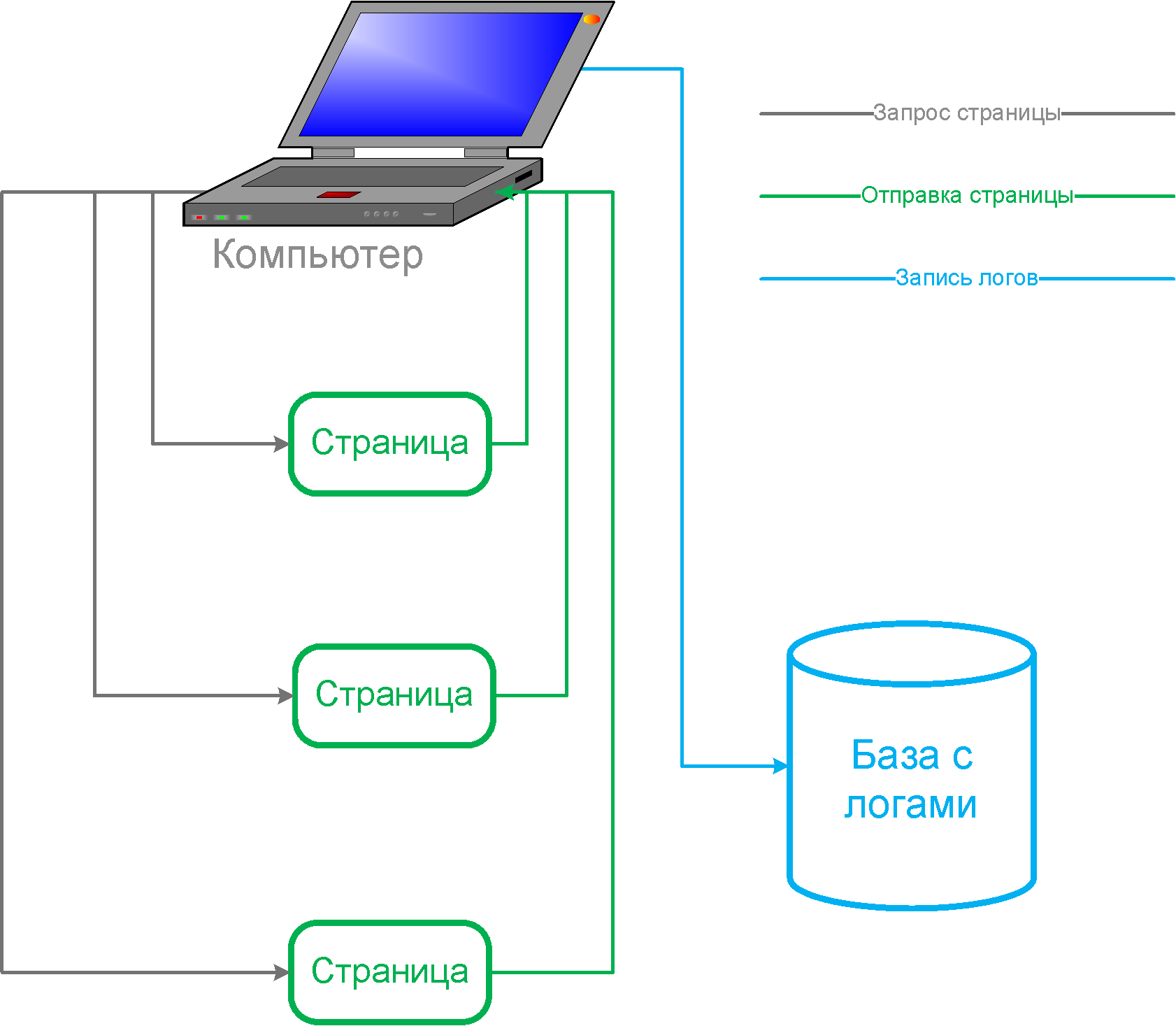
Плюсы:
- Возможен как подробный трекинг чтения конкретным пользователем, так и менее подробный (отправка только числа прочитанных страниц, без конкретизации чтения времени каждой из страниц и их номеров).
- При менее подробном учете статистики, данные занимают меньше места и уже хранятся частично агрегированными в рамках сессии чтения документа пользователем.
- Учитываются только фактически прочитанные страницы, упреждающее кеширование не искажает данные.
- Учитывается только органическое чтение книги в плеере. Показ обложек, деятельность поисковых роботов и т.д. в статистику не попадает.
- Универсальный способ, позволяющий использовать единую инфраструктуру ведения логов не только для книг, но и других типов документов.
Минусы:
- Зависит от плеера книги. Если есть мобильные приложения, они тоже должны использовать эту статистику.
- В браузере не работает без JavaScript.
- Учет конкурентных лицензий в некоторых случаях может обходиться (зависит от реализации защиты).
- Имеет погрешность измерений из-за неотправленных данных в момент закрытия браузера.
- Отправка данных дополнительными запросами увеличивает нагрузку на сервер.
Данный метод в большинстве случаев имеет наименьшие искажения и учитывает фактически просмотренные страницы и только людьми. Метод позволяет реализовать как очень подробные логи, так и только агрегированным. Рекомендуется его использовать в ситуациях, когда книги читают только через ваши плееры и все они совместимы со статистикой.
При грамотной реализации следует ожидать небольшое (5-10%) занижение фактической страницевыдачи.
Подсчет числа сессий (сеансов) взаимодействия с сайтом[править]
Внешние системы аналитики устанавливают куки в браузер и по ним определяют сессию. Таким образом, они не чувствительны к искажением из-за использования NAT.
Аналогичную куку можно ставить и записывать при использовании внутренних счетчиков и счетчиков на основе плееров. Учет сессий на основе анализа логов веб-сервера, в общем случае, не будет работать с куками и сессии работы с сайтом считаются по ip-адресам.
Соответственно, можно подсчитать число сессий как на основе счетчика логов, так и из системы внешней аналитики и сравнить результаты.
Достоверность статистических сведений облачных ЭБС[править]
Владельцы ЭБС мотивированы в хорошей посещаемости своих систем. Тем самым они мотивированы на завышение статистики, но не заинтересованы потерять доверие к своим отчетам. Для доступа к распространенным облачным ЭБС требуется авторизация, а статистика считается для каждой организации отдельно и пользователь должен быть ассоциирован с организацией. Поэтому отчеты облачных ЭБС не подвержены искажениям статистики из-за активности поисковых систем.
В случае, если все-таки есть недоверие к отчетам, я бы предложил потребовать от ЭБС установки независимых счетчиков (для каждой организации отдельный счетчик) и активизации соответствующего счетчика при посещении сайта. Полностью от накруток это не защитит, но результаты станут надежней.
Выводы[править]
Какой бы способ ведения статистики вы ни выбрали, он будет подвержен искажениям, т.е. подсчитанные данные не совпадают с реальными.
При допущении грубых ошибок в системе учета статистики, можно получить завышение измеренной книговыдачи и страницевыдачи в 10 и более раз. Следует убедиться, что измеренная статистика является именно органической и иметь примерное понимание насколько она искажена.
Полученная статистика должна рассматриваться критически и не должна существенно противоречить данным внешних аналитических систем (Google Analytics / Yandex Metrika).