Документы в формате PDF часто требуется отобразить на сайте в специальном плеере. Один из самых популярных способов - использование бесплатной библиотеки PDF.js и плеера этих же разработчиков. А часто просто выкладывают файл в PDF, открывающийся при клике во встроенный в браузер плеер.
Но на оцифрованных книгах PDF.js и встроенные в браузер плееры сильно тормозят. Почему?
Содержание
- 1 Способы отображения PDF
- 2 Процесс отображения PDF
- 3 Способы отображения PDF
- 4 Недостатки PDF.js
- 5 Когда PDF.js можно использовать
- 6 Когда PDF.js не следует использовать
- 7 Зачем для оцифрованных книг в PDF надо использовать специализированные плееры
- 8 Таблица сравнения разных методов отображения PDF
- 9 Сравнение PDF.js и встроенных в браузеры плееры со специализированными плеерами на оцифрованном контенте
- 10 Заключение
Способы отображения PDF[править]
Вначале разберемся с понятиями. PDF - бинарный формат, не является частью HTML и поэтому не может воспроизводиться браузером как часть веб-страницы. Для открытия PDF есть несколько вариантов:
- Скачать и открыть совместимой программой, такой как Adobe Reader (не удобно пользователям т.к. требуется длительное скачивание файла).
- Использовать плагин Adobe Reader (или аналог в виде Pdfium в Chrome и PDF.js в Firefox) для отображения прямоугольной области PDF с помощью внешней программы (ранее устаревший, но после появления встроенных плееров PDF в основных браузерах вновь актуальный способ).
- Использовать плеер для отображения PDF средствами HTML прямо на странице сайта.
- Использовать плеер, выполняющий рендеринг (отображение всех символов и рисунков в файле PDF в виде рисунка) на сервере (server-side rendering) с последующей отправкой рисунка в браузер.
- Использовать плеер, выполняющий рендеринг на клиенте (в браузере).
- Гибридный метод, объединящий предварительный парсинг и конвертацию PDF в специальный внутренний формат на сервере и рендеринг подготовленного файла на клиенте (в браузере).
Процесс отображения PDF[править]
Обязательные процессы для отображения PDF не зависят от того, отображается PDF браузером или десктопной программой. Различается то, на какой стороне делают те или иные процедуры.
Парсинг[править]
PDF - это бинарный формат, в котором фактически расположены буквы и рисунки в заданных координатах и надо эти буквы (глифы в шрифтах, заданные векторами) растеризовать (преобразовать вектор в растровое изображение) с некоторым размером глифа (буквы) в некоторой координате с некоторым разрешением (dpi).
Но чтобы получить отображение страницы в виде рисунка необходимо вначале распознать в бинарном формате буквы, рисунки, шрифты, страницы и т.п. графические объекты. Эта процедура называется парсингом. При этом PDF построен так, что вы не знаете точного местоположения конкретной страницы (а страницы не обязаны размещаться последовательно), поэтому если вам надо отобразить 234 страницу, парсер либо загрузит все предыдущие 233 страницы (последовательный парсинг), либо псевдослучайным образом будет "прыгать" по файлу PDF, пока не найдет нужную страницу. Есть еще вариант наличия специальной таблицы xref со ссылками между объектами, но она часто находится вконце файла и в таком случае последовательному парсеру придется прочитать весь файл PDF целиком, что для оцифрованной книги в 1 ГБ может занять значительное время.
При парсенге происходит и интерпретация данных и сбор PDF в некоторую структуру с данными, которую программа будет затем обрабатывать для отображения.
Рендеринг[править]
Итак, PDF разобран парсером полностью (последовательный) или частично, интерпретирован, страница найдена, шрифты прочитаны и после этого можно буквы (глифы) и рисунки отобразить. Этой задачей занимается рендерер. Рендереру необходимо передать информацию в каком разрешении производить рендеринг PDF, а на выходе ренедерер выдаст рисунок.

Зачем надо устанавливать рендереру разрешение? Дело в том, что в PDF все координаты откладываются в размерах физической страницы (т.е. в мм. как если бы PDF был распечатан на бумаге заложенного в PDF размера), а для отображения на ПК обычно необходимо указать число пикселей по горизонтали, в которых вы хотите получить отрендеренную страницу (рисунок), т.е. перейти от миллиметров (на самом деле points) к пикселям конкретного экрана.
Визуализация[править]
После того, как рисунок PDF-страницы получен, остаётся его отобразить на устройстве пользователя.
Способы отображения PDF[править]
Изначально файл PDF находится на сервере. Стадия визуализации в интересующих нас случаях всегда производится в браузере. А вот парсинг и рендеринг могут производится как на сервере, так и на клиенте (браузере). PDF - большой и сложный формат, поддерживающий разные типы шрифтов, алгоритмов сжатия текста и несколько форматов встроенных рисунков, поэтому довольно мало ПО полностью реализовавшего весь функционал PDF. Парсинг и рендеринг осуществляется всего несколькими программами, которые называют библиотеками рендеринга PDF.
Серверный рендеринг[править]
Сервер парсит PDF и рендерит его с заданным разрешением в виде рисунка. Затем рисунок передается по сети в браузер и отображается браузером тоже в виде рисунка. При этом PDF рендерится библиотеками в виде несжатого рисунка, поэтому после рендеринга дополнительно присутствуют стадии сжатия рисунка в один из подходящих растровых форматов (PNG, JPEG...) для уменьшения передаваемых по сети данных, а браузер эти рисунки декодирует и отображает в плеере.
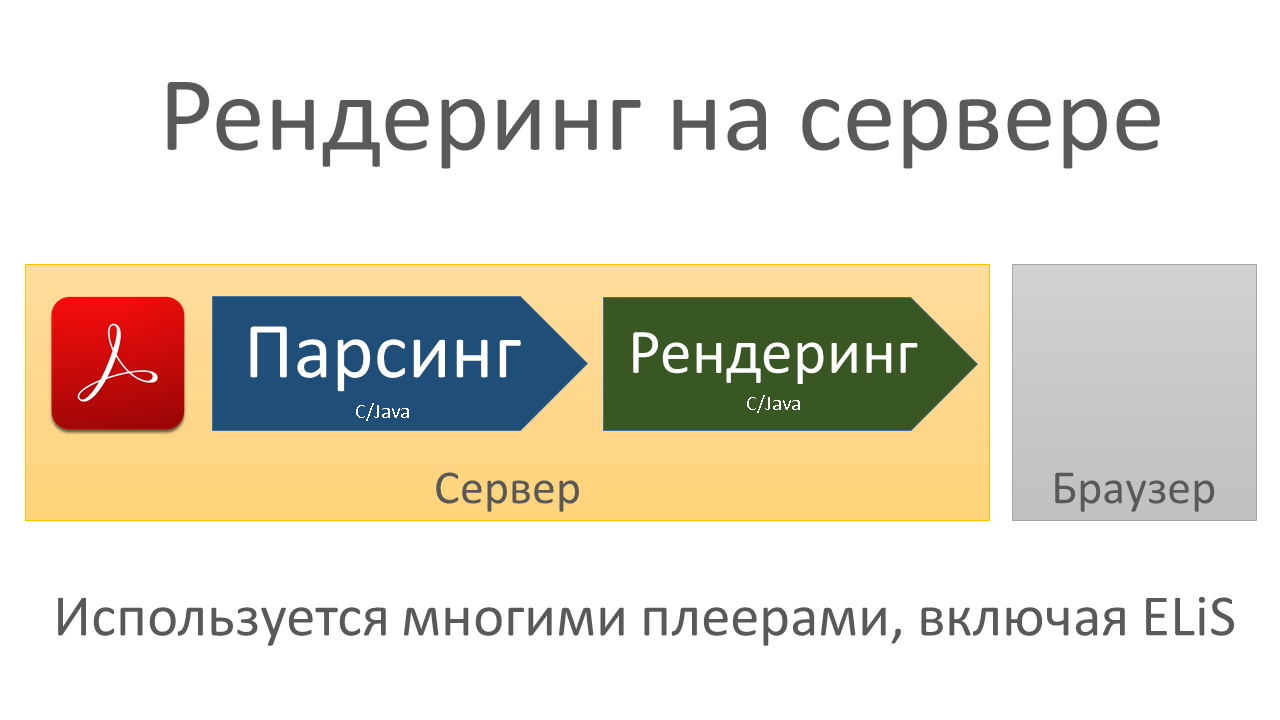
Плюсы: от браузера требуется только отображение рисунков, т.е. не нужно загружать какой-либо софт для рендеринга PDF с сервера, за счет чего быстрее производится отображение первой страницы. Также отображение рисунка хорошо оптимизировано и будет относительно быстро исполнятся даже на слабых и мобильных ПК.
Минусы: большая нагрузка на сервер (парсингом и рендерингом нагружен именно сервер) и большие рисунки, если рендеринг осуществляется в большом разрешении.
Многие коммерческие программы рендеринга PDF используют именно такой подход.
Рендеринг на стороне браузера[править]
Парсер и рендерер PDF пишутся полностью на JavaScript и исполняются в браузере. Вначале браузер скачивает PDF и сам же рендерит страницу и отображает в виде рисунка в плеере. PDF.js использует как раз такой подход.

Плюсы: единожды распарсив PDF можно прямо в браузере отрендерить его в разных разрешениях (нужно при зумировании на стороне плеера без потери качества) при малой нагрузке на сервер.
Минусы: часть спецификации PDF не поддерживается браузерами. Это касается как рендеринга шрифтов, так и рисунков в некоторых форматах, таких как JPEG 2000. Поэтому размер кода JavaScript для парсинга и рендеринга PDF занимает часто больше 1 МБ (у PDF.js 1 МБ). Браузер будет долго (особенно на низкоскоростных сетях) скачивать этот код JavaScript и долго (особенно на мобильных устройствах) его исполнять т.к. код JavaScript браузер тоже должен распарсить и исполнить, и только после этого возможна загрузка и отображение PDF. Причем сам рендеринг каждой страницы сильно загружает процессор т.к. число букв (глифов) на странице исчисляется обычно тысячами и эти глифы надо растеризовать и позиционировать. Таким образом рендеринг получается медленным, а на мобильных устройствах или в низкоскоростных сетях катастрофически-медленным. Также очевидным минусом является повышенное потребление трафика на многих файлах PDF.
Недостатки PDF.js[править]
PDF.js имеет все недостатки, свойственные своей архитектуре. Так размер минифицированного кода составляет около 1 МБ. При подключении на скорости 512 Кбит/c, скачиваться библиотека будет порядка 16 секунд и все это время браузер будет показывать "белую страницу" и не реагировать на действия пользователя. Только после того, как библиотека скачается и интерпретируется браузером, начнется загрузка PDF.
PDF.js не может одновременно на одной странице отобразить два PDF. Связано это с тем, что библиотека оперирует парсером в глобальной области видимости, т.е. на одной странице в одно время с помощью PDF.js может быть распарсен и интерпретирован только один PDF. В принципе, для большинства случаев это не очень важно, а там где необходимо, PDF можно загрузить в iframe (создать для него собственную область видимости), но при загрузке в iframe возникает проблема с тем, что сколько PDF вам надо загрузить, столько раз будет необходимо скачать и интерпретировать саму библиотеку PDF.js.
Для оцифрованных книг есть последний недостаток, ставящий крест на возможность использования PDF.js библиотеками при работе с оцифрованными книгами. Дело в том, что в оцифрованных книгах размер рисунков на страницах весьма не маленький, соответственно парсер начинает медленно работать при непоследовательном просмотре страниц (т.к. долго ищется нужная страница по большому файлу, который, напомню, надо скачивать с сервера, что значительно медленнее поиска файла на локальном диске), а когда эта страница все-же будет найдена, PDF.js сама на JavaScript будет долго декодировать немаленький рисунок (библиотека все делает с помощью JavaScript), а потом программно пересчитает размер итогового рисунка (чтобы вписать в нужные размеры) и только после этого отобразит в плеере.
Когда PDF.js можно использовать[править]
PDF.js можно использовать там, где:
- не требуется мобильный доступ;
- число пользователей низкоскоростных сетей невелико;
- файл PDF имеет небольшой размер (т.е. является преимущественно текстовым);
- файл PDF не состоит из страниц с очень большим числом глифов (букв) на одной странице (не газета);
- на одной веб-странице отображается один файл PDF.
Когда PDF.js не следует использовать[править]
Воздержитесь от PDF.js если у вас есть один из следующих случаев:
- велик процент мобильных пользователей;
- значимая часть пользователей имеет низкоскоростное подключение к сети;
- для отображения оцифрованных книг;
- требуется защита от скачивания PDF;
- за одно посещение многие пользователи просматривают 1-2 страницы;
- требуется возможность встраивания в сторонние сайты ("тяжелый" PDF.js может начать "тормозить" эти сайты).
Зачем для оцифрованных книг в PDF надо использовать специализированные плееры[править]
Рассмотрим как эту же задачу решают специализированные плееры на примере плеера библиотеки ELiS.
Размер кода плеера составляет 80 Кбайт и с учетом зависимостей 230 Кбайт в минифицированном виде (против 1 Мбайта у PDF.js).
В ELiS плеер имеет два режима рендеринга: векторный и растровый (картинка).
Растровый работает по классической схеме серверного рендеринга, причем под каждое устройство страница рендерится по ширине экрана (т.е. на мобильных устройствах с низким разрешением страница придет в меньшем разрешении, а значит за счет меньшего размера быстрее скачается), при этом на экране пользователя страница будет отображаться пиксель в пиксель, т.е. не происходит снижения качества из-за масштабирования страницы на стороне браузера. Также для повышения скорости в низкоскоростных сетях ELiS автоматически выбирает формат изображения из PNG (для текстового PDF), JPEG или WebP (для оцифрованных книг).
Растровый режим автоматически включается на медленных ПК для экономии времени загрузки страницы.
Векторный режим совмещает растровый рендеринг и векторный на стороне браузера. При нем на стороне сервера происходит разбор и подготовка PDF к отображению, но генерируется не рисунок, а промежуточный векторный формат, пригодный для прямого отображения в браузере (за счёт чего не надо тянуть в браузер JavaScript-код парсинга и рендеринга PDF). При этом, если в PDF есть вставки растровых рисунков, у этих рисунков происходит установка разрешения исходя из размеров экрана пользователя т.е. встроенные в PDF рисунки будут сжиматься на малых экранах для повышения скорости загрузки в медленных сетях.
При векторном рендеринге ELiS на сервере происходит парсинг PDF и рендеринг в совместимый с HTML векторный формат, а окончательный рендеринг в браузере встроенными средствами самого браузера. По сравнению с растровым рендерингом, векторный рендеринг после первоначальной генерации векторного представления страницы, нагружает сервер незначительно. Также векторный формат хорошо сжимается при передаче по сети без потери качества изображения, а при масштабировании страницы не требуется обращение к серверу.
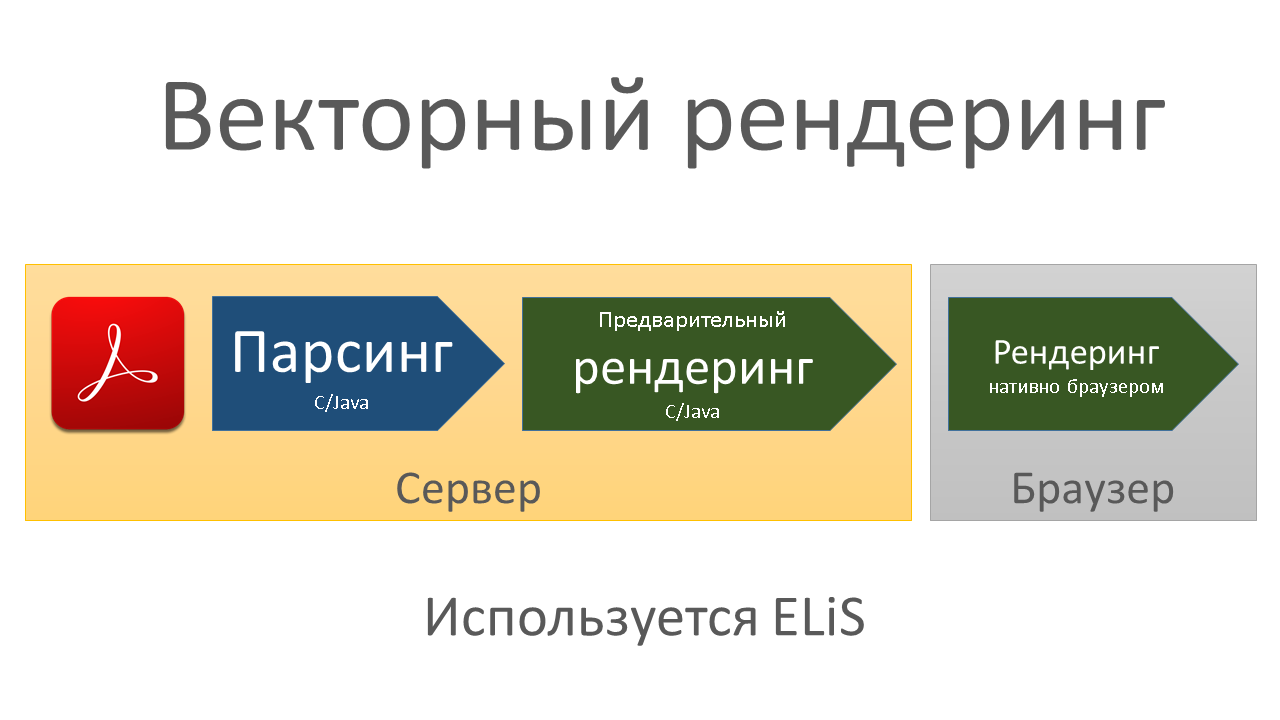
Зачем тогда нужен растровый режим, если векторный его превосходит по основным показателям? Чудес не бывает, чтобы произвести растеризацию текста (глифов) на стороне браузера всё еще требуются значительные ресурсы центрального процессора. Поэтому векторный рендеринг не подходит для медленных процессоров. ELiS автоматически определяет производительность процессора по началу загрузки страницы и активирует векторный режим рендеринга, если считает, что браузер достаточно производителен.
Таким образом ELiS переносит нагрузку на сервер, если браузер медленный и на клиента, если браузер быстрый.
Таблица сравнения разных методов отображения PDF[править]
| Метод рендеринга | Размер кода плеера | Скорость загрузки плеера | Нагрузка на сервер | Нагрузка на браузер | Скорость перехода по страницам | Подходит для мобильных устройств | Подходит для низкоскоростных сетей | Сохранение качества при зуммировании | Применимо для оцифрованных книг |
|---|---|---|---|---|---|---|---|---|---|
| Серверный рендеринг | Малый | Высокая | Высокая | Низкая | Высокая | Да | Да (для низких и средних разрешений) | Нет, но можно реализовать | Превосходно |
| Рендеринг на стороне браузера | Большой | Низкая | Низкая | Высокая | Низкая | Нет | Нет | Да | Плохо |
| Гибридный клиент-серверный рендеринг | Малый | Высокая | Средняя | Высокая | Высокая | Нет | Да | Да | Средне |
Сравнение PDF.js и встроенных в браузеры плееры со специализированными плеерами на оцифрованном контенте[править]
PDF.js встроен в Mozilla Firefox. Отличие встроенного в Mozilla плеере от размещенного на сайте плеере PDF.js в том, что при встраивании в браузер загрузка и интерпретация JavaScript кода PDF.js происходит с локального диска, а не с удаленного сервера, поэтому просмотр в браузере будет быстрее на время скачивания PDF.js.
Также PDF-плееры встроены в Google Chrome и Microsoft Edge, а в Internet Explorer можно установить плагин для поддержки PDF (Adobe Reader, Foxit Reader,...).
Сравнивать будем книгу, проигрываемую в плеере ELiS и эту же книгу, размещенную на статическом сайте (при его открытии запустится плеер, встроенный в браузер). Оцифрованная книга подобрана относительно не маленькая, размером 119 МБ на 200 страницах (в среднем 0.5 МБ одна страница) с текстовой подложкой.
Для сравнения скорости откройте ссылки:
- Плеер ELiS
- Плагин в браузере (открыть в Mozilla Firefox, Google Chrome и Microsoft Edge).
Обратите внимание, даже на довольно мощных процессорах в браузерах Google Chrome даже уже загруженная книга прокручиваться с большими рывками.
Чтобы оценить скорость перехода на некоторую страницу в файле PDF либо измените страницу в плеерах, либо пройдите на сотую страницу по ссылкам:
- ELiS
- Плагин в браузере (открыть в Mozilla Firefox, Google Chrome и Microsoft Edge).
Заключение[править]
Причина по которой PDF.js и встроенные в браузеры плееры PDF уступают специализированным плеерам очень проста: специализированные плееры специально подготавливают PDF для быстрого отображения в браузере, в то время как PDF.js и встроенные в браузер плееры получают PDF как файл (только по сети) и не имеют каких-либо предварительных оптимизаций контента, ускоряющих отображение. Для текстовых PDF относительно небольшого размера это может не иметь существенного значения, однако критично для больших PDF, созданных из оцифрованных книг. Также PDF.js в случае использования в качестве отдельного плеера потребует скачать 1 МБ кода и выполнить его, что также замедляет отображение, особенно на слабых ПК и в низкоскоростных сетях.
В случае, если на сайте библиотеки просто даны ссылки на PDF, при переходе по ним в новых браузерах запустятся встроенные плееры, которые также не оптимальны для оцифрованных книг.
Поэтому не используйте PDF.js для оцифрованных книг.
Для оцифрованных книг используйте специализированные плееры.
P.S. оценить скорость работы плееров распространенных в России электронных библиотек на мобильных устройствах можно здесь: http://elibsystem.ru/node/141, а наглядная демонстрация работы на смартфонах для некоторых библиотек доступна здесь: http://elibsystem.ru/static/LibrariesMobileCompatibility/